Abstract
While traditional and neural video codecs (NVCs) have achieved remarkable rate–distortion performance, improving perceptual quality at low bitrates remains challenging. Some NVCs incorporate perceptual or adversarial objectives but still suffer from artifacts due to limited generation capacity, whereas others leverage pretrained diffusion models to improve quality at the cost of high sampling complexity. To overcome these challenges, we propose S²VC, a Single-Step diffusion–based Video Codec that integrates a conditional coding framework with an efficient single-step diffusion generator, enabling realistic reconstruction at low bitrates with reduced sampling cost. Recognizing the importance of semantic conditioning in single-step diffusion, we introduce Contextual Semantic Guidance to extract frame-adaptive semantics from buffered features. This guidance replaces text captions with efficient, fine-grained conditioning, thereby improving generation realism. In addition, Temporal Consistency Guidance is incorporated into the diffusion U-Net to enforce temporal coherence across frames and ensure stable generation. Extensive experiments show that S²VC delivers state-of-the-art perceptual quality with an average bitrate saving of 51.62% over prior perceptual method, underscoring the promise of single-step diffusion for efficient, high-quality video compression.
🔍 Overview
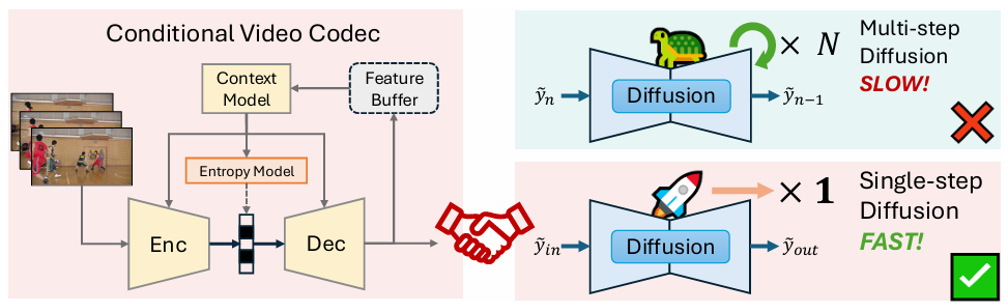
Our conditional video codec adopts a single-step diffusion model, which is especially critical for video where multi-step diffusion would make sampling many frames prohibitively expensive.
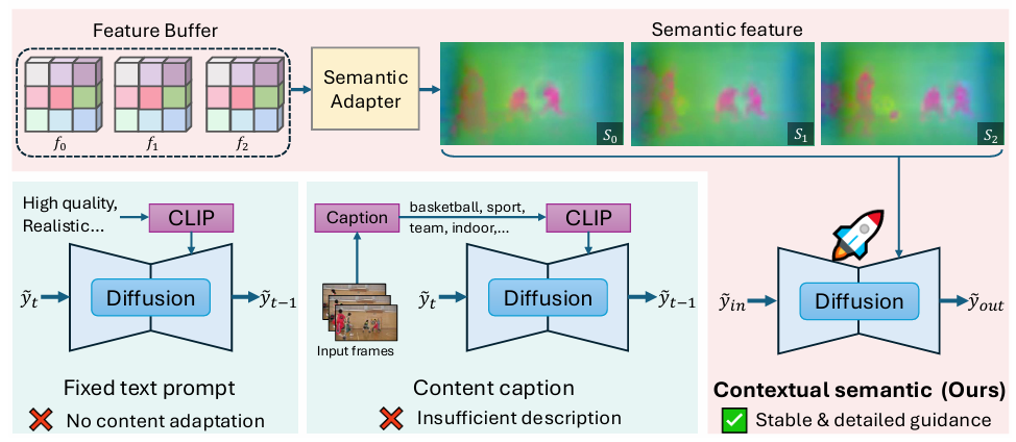
Comparison of semantic guidance. Fixed text prompts cannot adapt to dynamic video content, while captions lack fine-grained details. Our Contextual Semantic Guidance provides frame-wise detailed information without requiring additional caption or embedding models.
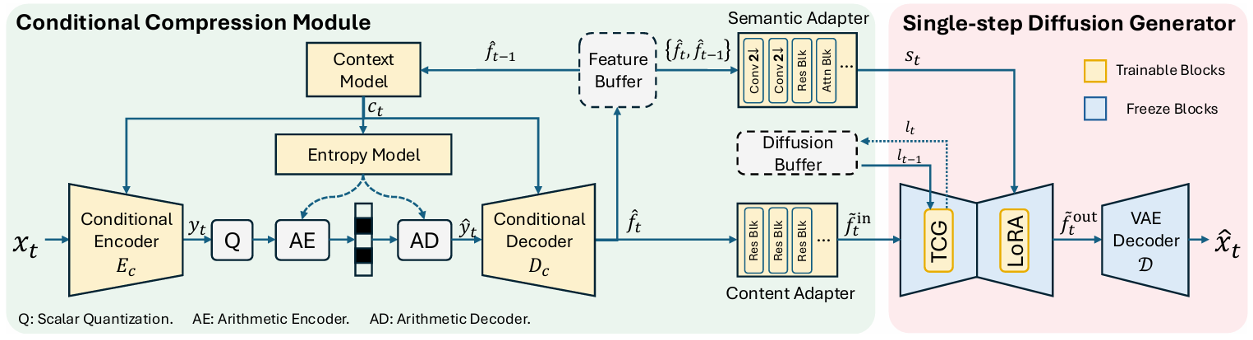
Overview of the S²VC framework. The feature buffer supports conditional coding, while the diffusion buffer enables feature propagation in TCG blocks for improved temporal consistency. LoRA is employed for efficient diffusion fine-tuning.
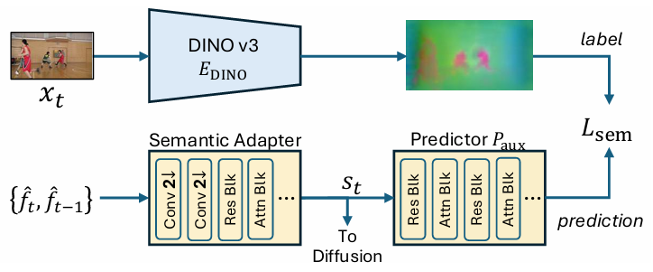
Semantic Distillation: DINOv3 acts as a teacher, transferring temporally stable, semantically rich features to the semantic adapter.
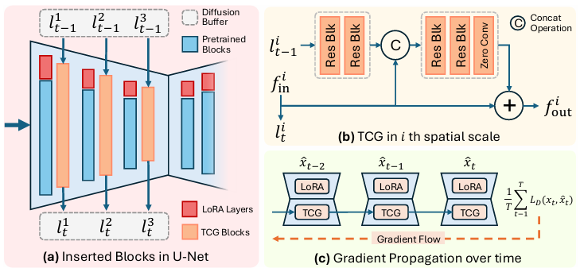
Temporal Consistency Guidance (TCG): plug-in blocks propagate features across frames and are optimized via cascade training.
📊 Experiment
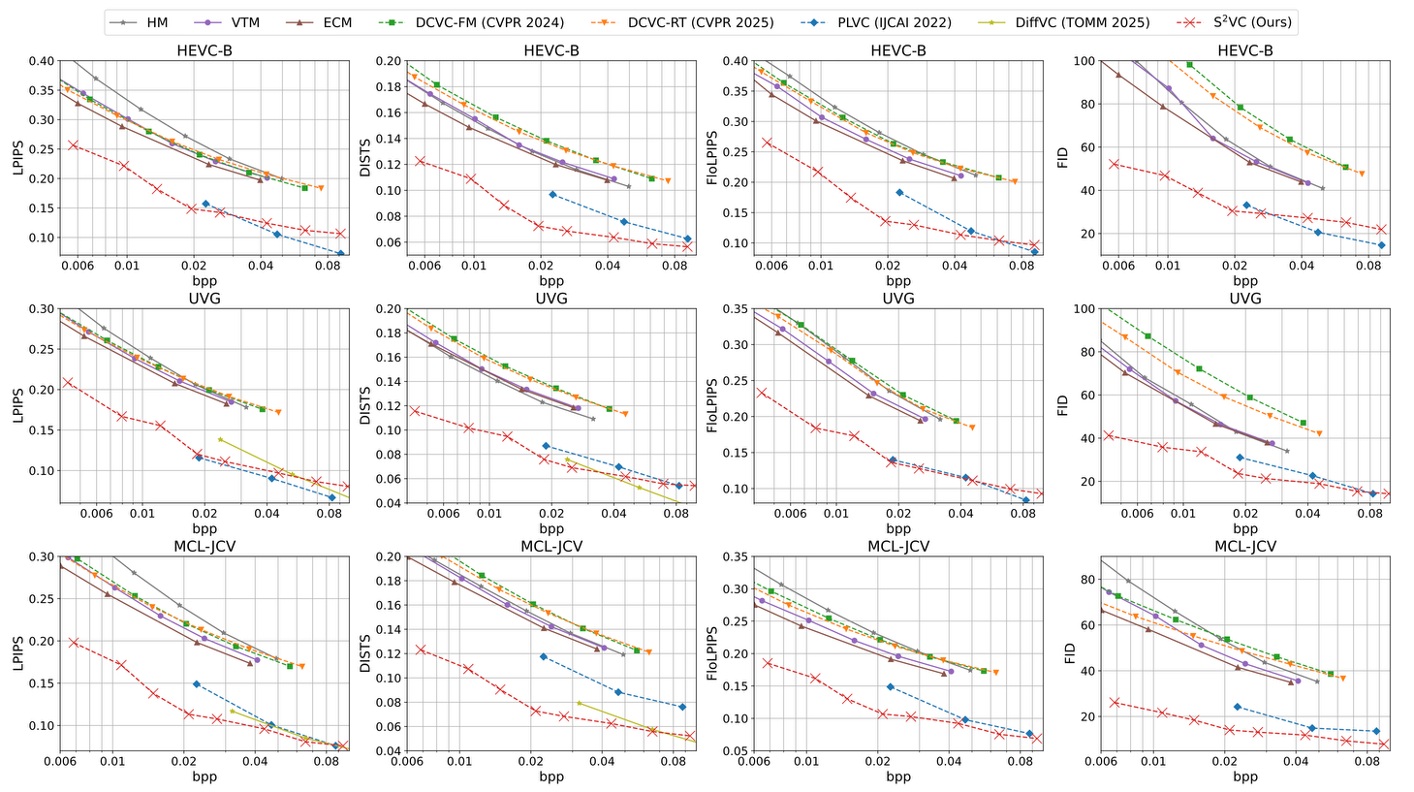
Rate-perception curves of S²VC and other video compression methods. S²VC achieves state-of-the-art perceptual quality across all benchmarks, with an average 51.62% bitrate saving over prior perceptual methods.

Visual comparisons. S²VC faithfully reconstructs fine details with high perceptual fidelity even under complex motion, while traditional and neural codecs produce blurry results or noticeable artifacts.
Poster
BibTeX
@inproceedings{xue2025s2vc,
author = {Xue, Naifu and Jia, Zhaoyang and Li, Jiahao and Li, Bin and Zheng, Zihan and Zhang, Yuan and Lu, Yan},
title = {Single-step Diffusion-based Video Coding with Semantic-Temporal Guidance},
month = {June},
year = {2026},
}